
Happy Halloween! It’s that time of year when we celebrate all things creepy, crawly, and spooky! So, in the spirit of the season, let’s look closely at one of the Internet’s most feared (and misunderstood) creatures: What are web crawlers? Hold off on that bug spray unless it’s a product you sell online because these spiders are 100% virtual and harmless. And if you sell bug spray or anything else online, pay close attention because web crawlers play a significant role in selling your products to potential customers.
What is a Web Crawler and How Does it Work?

Web crawlers are a bot operated by search engines like Google and Bing. A web crawler bot is like someone who goes through all the halloween candy in a disorganized candy store and puts together a display, so that anyone who visits the candy store can quickly and easily find what they want. To help categorize and sort the candy to display, the organizer will locate the name, brand, and some other information to determine why they are different.
Similarly, a crawler will find, sort and organize content found on the world wide web. These automated programs jump from link to link, searching for pages to add to an indexing database. According to DeepAI a web crawler is a computer program that automatically searches documents on the web. It’s that simple!
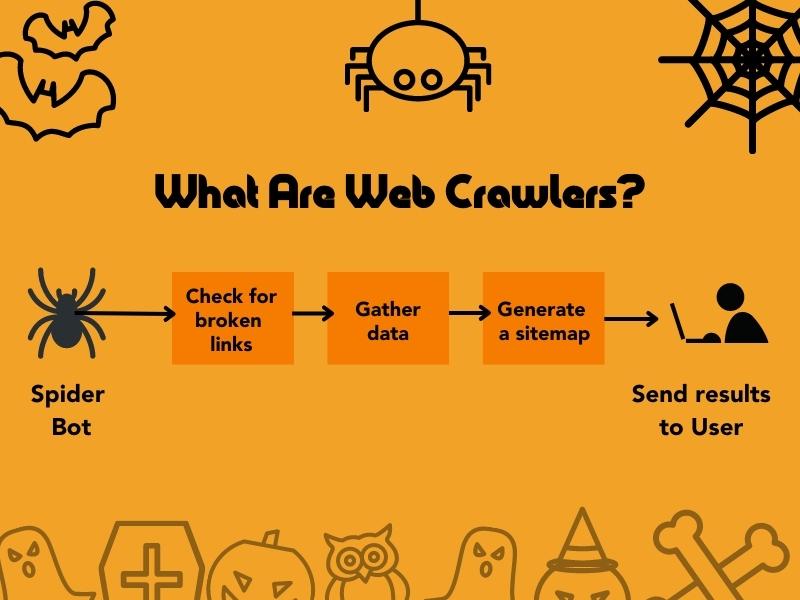
Why do they call them web crawlers? The internet is known as the World Wide Web, so it was only fitting to call these search engine bots “spiders” since they crawl all over the web, similar to a spider on a spiderweb.
While web crawlers are mainly associated with search engines and are used for several different purposes. For example, web crawlers:
- Check for broken links
- Automatically gather data
- Generate a sitemap
Of course, the most famous web crawler has to be the one that’s responsible for answering over 89 billion questions per month with a highly relevant list of URLs to match any number of topics. The best crawling capability makes Google the best search engine to get your information.
Meet GoogleBot – A Web Crawler Example That Collects Massive Amounts of Data
Is Google a web crawler? Not exactly, it’s a big company that does a lot, but a crawler is one of their most well-known pieces of software. GoogleBot is a bot that searches and indexes content on the internet so that it can appear in Google Search results.

How Do Creepy Web Crawlers Find Websites for a Search Engine?
For web pages to appear as search results, web crawlers like GoogleBot must first find them. Before a site shows up on your iPhone, it was indexed through a process that began with crawling.
Once found, web crawlers send out little robots called ‘spiders’ to scour the internet and collect data. These spiders follow links from page to page until they’ve discovered every nook and cranny of the web.
Once a spider has found a web page on a network, it sends the information it gathered back to Google, where it’s indexed and stored. The next time you search on Google, the web pages that are most relevant to your query will be pulled from the index and displayed in the search results. That’s a simple explanation on how web crawler applications work.
Outside of Google, How Are Web Crawlers Used?

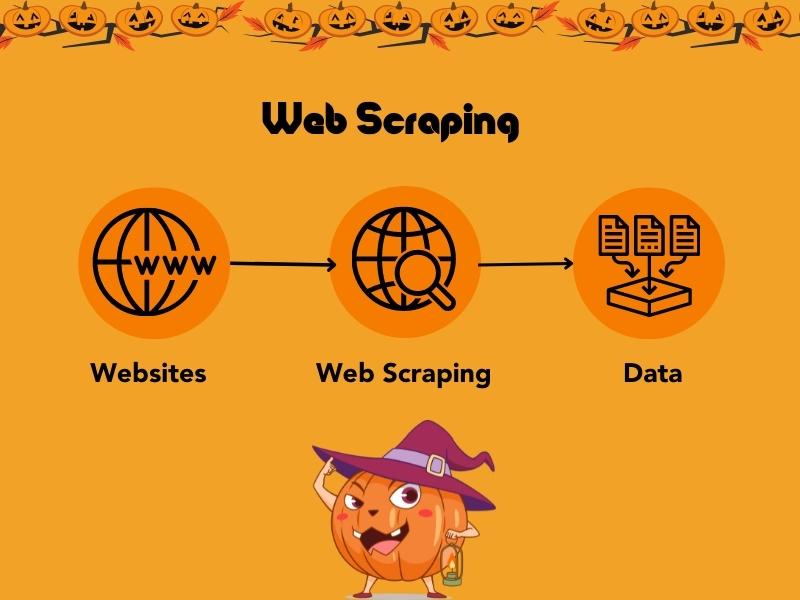
Web crawlers monitor web server availability, collect data, and get web scrapes.
Web crawlers deploy to crawl specific websites or pages looking for particular types of information. For example, a web crawler collects contact information like email addresses or phone numbers from websites. This collection is web scraping, the process of extracting data from websites. Web scraping can collect data about prices and product availability or for research projects. There are many free and paid tools out there for scraping, and I’ll briefly describe the one you might have heard of before we dig into the most frequently asked questions about bots and crawling.
Free Network Scraping Tools Like Octoparse
Now that you know this much about crawling, I’d recommend trying out a tool that goes through websites looking for information like Octoparse. Learning digital marketing through blogs will only get you so far without some hands-on experience. Many web scraping tools are available, but Octoparse is one of the most user-friendly. It’s a visual web scraper, meaning that you don’t need to know how to code to use it. Octoparse can help you quickly collect data from any website with its point-and-click tool. You can find contact information, social media profiles, and more with Octoparse, which can help with anything from researching and citing statistics for your upcoming blog to building a list of contacts for sales outreach on social media.
Frequently Asked Questions:
Anytime the subject of crawling comes up, there are many technical questions about the data. These questions range from security to the fundamentals of transmitted data. Here are a few more common questions I’ve encountered when discussing the subject with our clients at Webology.
Are Web Crawlers Legal?
Web crawlers are legal in most cases as long as they adhere to specific guidelines. For example, web crawlers must respect the robots.txt file on a website, which outlines parts of the site that are crawled and can’t. Additionally, web crawlers should not overload a website with too many requests, which can cause the site to crash. Mainstream search engine bots like those used by Google or Yahoo typically don’t cause issues like this unless your site’s on a server with resource issues. Finally, web crawlers should not collect sensitive information like credit card numbers or login credentials.
How to Block Web Crawlers

Blocking web crawlers depends on how you built the site. But, in almost every case, it is best to list specific crawlers you want to block in your robots.txt file. For example, the following code would tell all web crawlers to stay away from the “disallow” directory:
User-agent: *
Disallow: /disallow/
Of course, you can also disallow an entire website from being crawled. For example, the following code would block AhrefsBot from crawling your site:
User-agent: AhrefsBot
Disallow: /
If you want to get specific, you can even block web crawlers from accessing certain files on your website. For example, the following code would block web crawlers from accessing any files that end in “.jpg”:
User-agent: *
Disallow: /*.jpg$/
The robots.txt file is a great way to control which web crawler bots can access your site and which parts of your site they can crawl. However, it is essential to remember that web crawlers are not required to obey the rules you set in your robots.txt file. They typically do respect your wishes, but it’s not guaranteed. You have zero control when it comes to Google. They will often see that pages were blocked by mistake and index them anyway. So if you want to keep web crawlers away from certain parts of your site, it is best to use other methods, such as password-protecting those areas.
Why Would You Want To Block Web Crawlers?
One of the most common reasons to block a particular web crawler is related to common SEO best practices. Third-party tools like AHREFS and SEMrush allow anyone to view a large portion of any website’s backlink profile. Competitors can see your top links and start mining that data for their link-building efforts. So, many times, the user agent of these 3rd party tools gets blocked in a robots.txt file to prevent the competition from doing a thorough link analysis.
Can Google Web Crawlers Read CSS?

Google and other web crawler bots can read CSS, but they don’t always render pages as a web browser would. Lack of rendering can cause problems when Google tries to index a page. The reason is the web crawler may not see all the page content.
One way to ensure that Google can see all the content on your page is to use the “Fetch as Google” feature in Google’s Search Console. The search feature will allow you see how Google views your page. You can make changes to ensure that the web crawler can access all the content on your site. I’ve seen several examples over the years where sites didn’t rank as high as they could in the search engine results because the web crawler simply did not find the content.

What is a Crawl Budget?
It’s a term that describes the resources a web crawler has available to review your website. Web crawlers are a type of bot that is typically operated by search engines like Google and Bing. Server resources aren’t unlimited, even for companies like Google. With billions of websites online today, it has become necessary to limit the amount of data and bandwidth allocated to web crawlers. The crawl budget, the number of web pages or files a search engine bot can and wants to crawl on your website during a given period, activates. Crawl budget is It’s important to note that not all web crawlers have a set crawl budget, but Google does.
The size of your website and the quality of your content plays into how much Google crawls. If you have a smaller website with high-quality content, Google will likely want to crawl more of your pages since there’s a higher chance of finding new and relevant information.

Conversely, if you have a large website with lower-quality pages, duplicate content, or other SEO issues, Google may not want to crawl as much of your site since there’s a higher chance it will find nothing new or relevant.
The primary goal of web crawlers is to discover new and updated content. To do this, they must visit web pages and follow links to other pages. The number of times a web crawler visits your site is called its “crawl rate.”
You can think of your crawl rate as an indication of how important Google (or any other search engine) thinks your website is. If you have a high crawl rate, it means that Google thinks your site is essential and wants to visit it often to find new content.
Contact Webology

Fixing creepy crawl rate issues often leads to higher rankings and more traffic from Google. If you’re unsure how to protect your site and improve your crawl rate, contact the expert team at Webology to schedule a complimentary diagnostic of your website’s technical SEO metrics. We understand all the latest tactics to optimize crawl rates, even on the largest of sites with thousands of pages to manage. Reach out today and let us help you increase your website’s traffic from web crawlers.

